������ 11�� 13�� ���ǵ� �����ڸ��� �繫�ǿ��� �ڻ��� ���� ���μ��� E5 ��ǰ���� ���ս� ������ ��ǻ���� ���꼺�� ȿ���� ����, ���� ���� ����ȭ ������ ������ �� �ִ� ���� ���� Phi �����μ��� ��� ���ڰ���ȸ�� ������.

���� ���� Phi �����μ����� CPU (�߾� ó�� ��ġ)�� ���� ����ȭ�� ������ �� �ִ� ������ ������ �ϴ� ���� ��ǻ�� ���ӱ⸦ ���Ѵ�. ���� Phi �����μ����� ���� �ڵ�� Knights Ferry �Ǵ� Knights Corner�� �Ҹ�����.
������ �ٳⰣ�� ������ ������ �������� ������ ��ǻ�� (HPC)�� �ܳ��� ���� Phi�� ������ ������ �� ���ӱ⸦ ���� ���� ������ ȿ������ ������ Ž��, ���� ġ��� ���� �� �۷ι� ����� ���� �����ڵ��� ����� ���� ���� �ذ��� ���� ������ ��ǻ�ð� �ùķ��̼� �ɷ��� ��ħ�� �� �ְ� �Ǿ���.
���� ������ ��ǻ�ð� �м��� ���� ������ ���� ���� Phi�� ���� ���� ��ǻ�� ���ӱ�� 22nm �̼������� ������� ��Ʈ�� ���� ������ ���� ��Ȯ�� ��� �� �������� �����ϸ� �����ҿ� ���� ���� ������ �䱸�� ���꼺�� ������ �� �ִ�.

���� ���� Phi ��ǥ�� ������ �����ڸ��� �ֿ��� �̻�
�����ڸ��� �ֿ��� �̻�� �̳� ���� ���� Phi ��ǥ�� �����ߴ�. ������ ������ ����ȭ�� ��ũ�ε忡 �ְ� ������ �����ϴ� ���� ���� Phi �����μ��� ������ ���� �ռ� ���� ���� ���� �����ϸ� ���� MIC ��Ű��ó ��� ���� ���� Phi �����μ����� ���� ���� ���μ����� ������ �ڿ� ����, ������ �� �پ��� �о߿��� ������ �ֵ��ϴ� ������ ����ȭ�� ���ø����̼��� ���� ���� ���ɰ� ȿ������ ������ ���̶�� ���ߴ�.
���� ���� ���� Phi�� 2018����� ����� (Exacale) ��ǻ�� (��Ÿ���� õ �� �̻�)�� ���ϱ� ���� ������ ������ ������ ���̶�� ������.
���� ���� Phi ��������� ����� ������ ����

���� ���� Phi�� ���� 2004�� ���� ����ȭ ��Ű��ó�� ���� �ʿ伺�� ���� ������ �����ִ� �̷� ���ø����̼� ���� ����� IDF�� CTO ������������ ��ô� (Tera)�� �ô��� ���� ��ǥ�� �������� 2007�� 2������ 80 �ھ� ���÷ӽ� ����ġ ���μ��� (Teraflops Research Processor) �ڵ�� ���� (Polaris)�� ISSCC���� ��ǥ, ������ ���� Ĩ �� 1�� �ε��Ҽ��� ���� (1 ���÷ӽ�) ������ �����־���.
���� 2009�� 12������ ���� Ĩ Ŭ���� ��ǻ�� (Single-Chip Cloud Computer, SCC) �ڵ�� �� ũ�� (Rock Creek)�� �����߰� ���� Ĩ���� 48���� ���� ��Ű��ó �ھ �����ߴ�.
2010�� 5������ ���� ������ǻ�� ���۷������� ������ ��ǻ���� ���� MIC (Many integrated Core) ��Ű��ó ����, 2012�� 6�� ���� ������ǻ�� ���۷������� ���� MIC ��Ű��ó ��� ���� ���ö� ���� ��� DP ���� (DP Linpack)�� �ÿ��� �����ϰ� ���� Phi �����μ����� ����ߴ�. ���� ���� Phi Ŭ�����ʹ� ���� ��� �� ������ǻ�� Top 500 ����Ʈ �� 150���� ����Ǿ���. ���� ������ǻ�� Top 500 �ű� ���� ����Ʈ �� 91%�� ���� ���μ����� ž��ǰ� �ִ�.
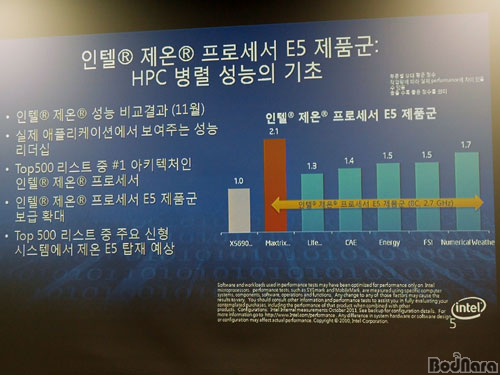
�̷��� ������ ���� ������ 2012�� 11�� ���� ���� Phi�� ���� ��������� 8�� �̻� ���ӵǾ�� ������ ������ ��°� ��ũ���� ��ǻ���� ���ο� �ô� ����, �Ŵ� �ھ� ������ ���� ��ǰ ��� �������� �ְ� ������ �̲�� �� ���� ���̶�� ������. ���� ���� Phi �����μ����� ���� ȿ������ ��Ʈ�� 2.44 �Ⱑ�÷ӽ��� ����� ������ǻ���� ���� (Beacon)�� ������ 7�� �ý����� ž���ϰ� �ִ�.
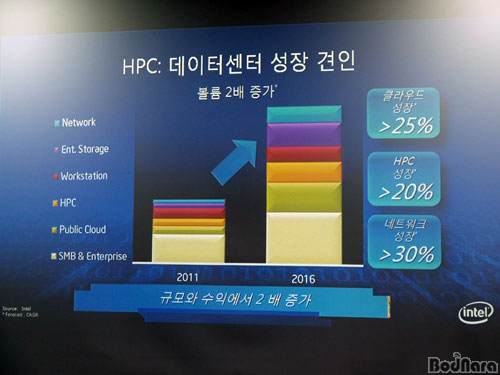
������ ������ ��ǻ�� (HPC) ������ �����ͼ��� ������ �Ը�� ������ 2011����� 2016�� ���� 2��� ������ ������ ���������� Ŭ���尡 25%, ������ ��ǻ���� 20% �̻�, ��Ʈ��ũ ������ 30% �̻��� �̷���� ������ �����ߴ�.
���� �̷��� ��ȭ�� �Բ� ���Ŀ� ���� ��, �Ƿ� ����, ������ ���� ���� ������ ���翬��, ���� �о� ������ ���� �м�, �Ż�ǰ ������, ������ ������ ���� ������ ������� �䱸, ���� �Ⱥ��� ���� ���� ����, �������� ���� ���� ���� ���� ���� �Ⱥ� ���� ���� ���� ������ ��ǻ���� �䱸�ϴ� ��ȸ �������� ���������� �����ϰ� �־� �̸� �ذ��� �ַ���� ���������� �䱸�ǰ� �ִ�.
��� ȿ������ ��� ����, ���信�� ��������� ���� ����, ������ ���� Ȯ�� �� ���ü��� �䱸�Ǵ� ����ȭ�� ����ȭ�ǰ� ������ ������ ��ǻ�� (HPC)�� �̸� �������� ȿ������ ���꼺, ������ �̲�� �� ���� ������ �˷�����.

������ �̷��� ����ȭ�� �䱸�Ǵ� ������ Ÿ������ ���� ��ǻ�� �귣�忡 ���� ���� Phi �����μ����� ������ ���� ���� ���� ���μ����� ������ ȯ���� ������ �� ���� ���̶�� ���ߴ�. ���� ������ ����� �̼� ũ��Ƽ��, ��ũ���� ��ǻ�� ȯ�濡 �ֻ��� ���μ��� ������ �����ؿԴٸ� ���� ���� Phi �����μ����� ���� ������ ����ȭ ���ɿ� ����ȭ�ϰ� �ִ�.
���� ���� ���μ����� ���� ���� Phi �����μ����� ������ ���� ���� ȯ���� ���� ������ �ڵ� �� ����ȭ�� ������ �̿��� �� �־� ������ ���Ǽ��� ���� ������ ���������شٰ� ������. ���α��� ���� ��, ������ �پ��� ���� ���� �ϰ����� ������ �� �־� ����Ʈ���� �ڵ��� ���� ����, ����ȭ �� ���� ���⼺�� ���ҽ�Ų��.
���� �ϵ���� ����� ���� ������ ���ø����̼� ����ȭ ���α����� ����ؾ� �ϳ� ������ ���� ����� �����ڰ� ���ο� ������ ������ ���α��� ���� ���� �ʿ� ���� �Ϲ����� �� ����, ���迡 ������ ������ �� �ְ� ����ȭ �ڵ忡 ���� ���ڴ� ��ǻ�� ȯ�� ���ݿ� ������ ������ ���̶�� ���ߴ�.
���� ���� Phi �����μ��� ����ȭ�� ������ ����, ���� ���°�
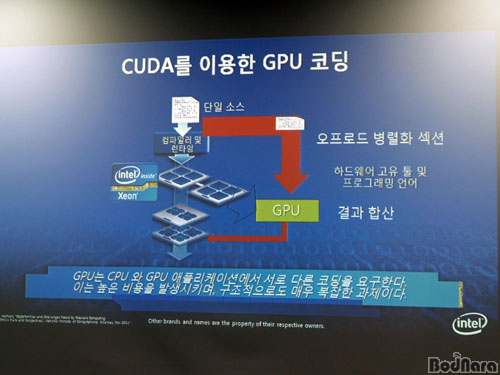

GPGPU�� AMD�� ������ (NVIDIA)�� GPU�� ���� �����ǰ� �ִµ� GPU�� CPU�� GPU ���ø����̼ǿ� �´� ���� �ٸ� �ڵ��� �䱸�ȴ�. �̷� ���� ���� ���� ���������ε� ���������� ������ ���� �� �´� �ڵ����� ���� ���� ���� ������ ���Եȴ�. ���� ���� ���μ����� ���� Phi �����μ����� ���� x86 �ھ ������� ��������� ������ ���� ���� ���ɾ�, ���̺귯��, ������ ����� �� �־� GPU�� ���� ������ ���� ���� �ذ��� �� �ְԵȴ�.

����ȭ�� ���� �ڵ������� �����ϰ� 2�� ������ �߰����ָ� ���� ���� ���μ����� ���� ���� Phi �����μ����� �����Ͽ� ����ȭ�� ó���� ���� ����������.

������ �پ��� ���� ���α��� �� ������ ���� �����ε� ���ɾ� ��� ���� ���� ǥ�� ���ٹ��� �����Ѵ�. �������� ���ڰ� ������ �� ���� �ٸ� �� Ȱ���� ������ ȣȯ�� ��������� �̸� ǥ��ȭ�ϰ� �پ��� �ϵ���� ���� ���� ǥ���� ���� OpenMP 4.0�� ������ ��ȹ�̴�. ���� �����Ϸ� C/C++ �� ��Ʈ�� �����Ϸ��� 2013�� 1�� ������ ������ �����ߴ�.

������ ���� ���μ����� ���� Phi �����μ����� �������� ����ȭ�� ����ȭ�� ��ȹ�̴�. ���� ���� ���μ����� ���� ���� Phi �����μ����� ������ ���� �ڵ� ������ �ִ� 145��, �ϵ���� ���� ���� ������ 2.3�谡 ���� ������ �����ߴ�.
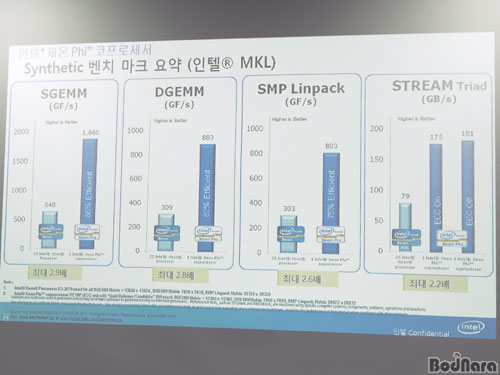

���� ���� Phi �����μ����� ���� ���μ��� �ܵ��� ���� ���� ó�� ������ �����ϸ� ���� ���ø����̼� ó�� ���� �ι������� �������� ����� �̷����.

���� ���� Phi�� ���� ���μ����� ���� ���� ��Ű��ó�� ������ ���� ���� ���α��� ȯ��� ���� ���� ���� ����� �����Ѵ�. ���� �̸� ���� �ڵ� �� ���α��� �� �����Ͽ� ����� �� �ֱ� ������ ���� ȯ�濡 ���� ������ ����������.
���� ���� Phi �����μ��� Ȱ�� ��� �Ұ�


���� ���� Phi �����μ��� ��ǥ�� �Բ� �ѱ����б������������ (KISTI) ������ǻ�� ������ ��ȫ�� �ڻ�� ���ڵ����� (KMD) ����� KMC, �ѱ�������ſ����� (ETRI, Electronics and Telecomunications Research Institude)�� ������ (Big Data ����Ʈ���� ������ Ŭ���� ��ǻ�� �������� �ֿ� ������ ���� Phi �����μ��� ������ �ڵ�� Knights Ferry�� ���� Phi�� ������ ��ʸ� �Ұ��ߴ�.



KISTI�� ���ڵ����� ������ ���� ���� E5500 �迭���� ���� Phi �����μ����� Ȯ�� ������ �ھ� ������ ���� �������� ���� ��� ����� ���� �� �ִٰ� �������� ������ ������ǻ�� ���� ���� �ùķ��̼��� ���� ����ȭ�� ���ɰ� ȿ������ ���� �� �־��ٰ� ������. Ư�� �ϵ���� ��� ���� ����ȭ�� �߿����� ���������� ���� ���� Phi �����μ����� AVX 256bit ���ɾ�� 512bit ���� Ȯ�� ���ɾ� ó���� ������ �������� GPU ��� CUDA�� OpenCL ��� ���α����� ���� ���ٰ� ����ȭ, �ʺ��ڳ� �߱� ���α����� ���α� ���� ���̼��� �����Ѵٰ� ���ߴ�.
ETRI�� ���� MIC ��Ű��ó�� Ȱ���� ����ü �м��� ��Ÿ�÷ӽ��� ������ǻ�� �ٽ� ����� ����, �����ϰ� ������ 2012�� 12�� MAHA ������ǻ�� �ý��ۿ� ���� ���� E5 ���μ����� ���� ���� Phi ��� 50���÷ӽ� ������ �ý����� ������ �����̴�. ETRI�� MAHA ������ǻ�� �ý��ۿ� ������ 2012��� 100TeraFlops���� 2013��� 200TeraFlops, 2014��� 250TeraFlops, 2015��� 300TeraFlops���� �ý��� �ε���� Ȯ���س��� ��ȹ�̴�.
���� ���� Phi �����μ��� ��ǰ��


���� ���� Phi �����μ����� 2013�� ��ݱ� ��� ������ 3100 �ø��� �����μ��� ��ǰ���� 2013�� 1�� 25�� ���� ���ǿ� ���� 5110P �����μ��� ��ǰ���� �ִ�.
���� ���� Phi 5110P (P�� �нú� �� ���) �����μ����� ������ ������ ���� �� ������ ������ ���� ������ ��� �� �ٿ�� ���ø����̼��� ���� ���� ���� �� �뷮�� ������ Ȯ���� �� ������ 3100 �ø��� �����μ����� ���� �پ ���� ��ǻ�� �ַ������ �ڿ� ���� ���ø����̼��̳� ���� �ùķ��̼� �� ��ǻ�� �������� �۾��� �����ϴ�.

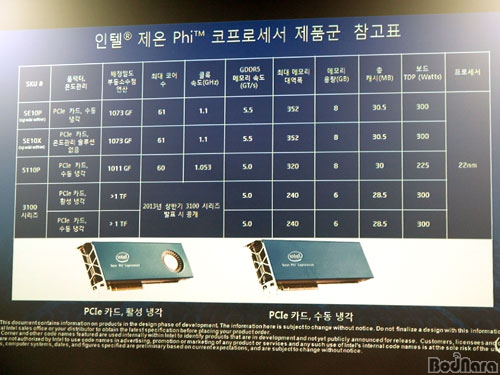
���� ���� Phi 3100 �ø��� �����μ����� 1000 �Ⱑ�÷ӽ� (GigaFlops) �����е� �̻� (��ũ)�� GDDR5 6GB �� 240GB/s �� �뿪��, �ɵ�/���� �����ͷ� TDP 300W�� �����Ѵ�. ���� ���� Phi 5110P �����μ����� �ִ� 1010 �Ⱑ�÷ӽ� (Gigaflops) �����е� (��ũ), GDDR5 8GB �� 320GB/s �� �뿪��, ���� �����ͷ� TDP 225W�� �����Ѵ�.
���� ���� Phi �����μ��� 5110P�� ���ú��� OEM �ֹ��� �����ϸ� ���� ������ 2013�� 1�� 28��, ������ 1,000�� ���� �� 2,649�� ($2,649)��. ���� ���� Phi �����μ��� 3100 �ø���� �̺��� ���� 2013�� ��ݱ� ��� �����̸� ������ 2,000�� ($2,000) ���ϰ� �� �����̴�.
���� ���� Phi ������� ���� ����� ����
���� ���� Phi �����μ��� ��ǰ���� ���� �� ��Ʈ �� ������ �����ϸ� �ھ�� ������ ��, ���̵� SIMD, ij��, �� �뿪�� �� ������ ���� ������ ��ǻ�� (HPC) ȯ���� �����Ѵ�. ��� �о߿� �ְ��� ������ ������� ������ ����ȭ ���ø����̼ǿ� �����ϰ� �ε��Ҽ������� �ɷ��� �����ڿ� ���� �پ�ų� ����� ������ �����ϸ� 22nm �̼������� �������� �� ������ ȿ������ �����Ѵ�. ���ɻ� �� �ϵ���� ��ü ���ݰ������ �����ϸ� PCI-Express �ݿ� �´� TDP 300W ������ ������ �����Ѵ�.
���� ���� Phi �����μ����� ������ ����ȭ�� �뷮 ���� ó���� ���� ��������, ���� �� �� ������ǻ�� ������ �ð� ���� ���� ���μ����� ���� ���� Phi �����μ��� ������ ��Ÿ�� ��ǻ�ú��� õ �� ���� ����� ��ǻ�� �ô븦 �մ�� ���̶�� ������ ���ߴ�.
���� ���� Ŀ�´�Ƽ �� �ֿ� OEM ��ü�� �������� ������ ���� ������ �����ڿ� ������, �����ڵ��� ������ ��ǻ�ÿ� ���� ���� ���� ����������. �帲���� �������� ���� ������ ������ ���� ��� ���� ���� Phi �����μ����� Ȱ��ǰ� ������ ���� ��ð� �̷���� ��ŭ �پ��� �䱸�� ���並 �ݿ��� ������̳� ���ø����̼� ������ ���� ȭ��� ������ �����ߴ�.
���� GPU���� ���£ ���� ������ ������ ���а��� �䱸�� ���� �����Ͽ� �̸� �����ϰ� ������ ��ǻ�� (HPC)�� ���� �ܰ��� ������ ��� ���� ������ ��ǻ���� �ε���� ���� �������ѳ��� ���̶�� ������.

���� 50�� �̻��� �����簡 ���� ���� Phi �����μ��� ����� �ַ���� �����ϰ� ������, ���̼�(Acer), ������(Appro), ���̼���(Asus), ��(Bull), ���ѽ�(Colfax), ũ����(Cray), ��(Dell), ������ũ(Eurotech), ������(Fujitsu), ��Ÿġ(Hitachi), HP, IBM, �ν���(Inspur), NEC, ��Ÿ(Quanta), SGI, ���۸���ũ��(Supermicro), Ÿ�̾�(Tyan) ���� ���Եȴ�.
���� ���� Phi �����μ��� ��ÿ� ���� ���̾� ����̾�Ʈ (Diane Bryant) ���� �λ���� ������ ���� Ŀ��Ƽ�� �ý��� �� (Intel Data Center and Connected Systems Group) �Ѱ� �Ŵ����� "���� ���� Phi�� ���ο� ������ ���� �� �߸����� ����� (Exascale) ��ǻ�ÿ� ���� ������ ��Ȯ�����ִ� ���� ������ ���帶ũ�� �� ��"�̶�� "���� ���� ��ǰ���� ���� ���� Phi �����μ����� �پ ���ɰ� ȿ����, ���α����� ���� ������ ����ȭ�� ���ø����̼��� ���� �� �ִ� ������ �Ը� �ٲ� ���� ���̴�. �̷��� HPC�� ���ο� ��� ����� 21�� �̳��� ���� ��Ȯ�� ���� ������ ���� ġ��� ���� �� ���� ���谡 �����ϰ� �ִ� ���� �ذ��� ���ɼ��� �Ѵܰ� �մ�� �� ��"�̶�� ������.
���� Top 500 ������ǻ�� ������ ������ ��ǻ�� �������� �����ϰ� ������ �� 40�� Top 500 ����Ʈ �� 75�ۼ�Ʈ(379�� �ý���) �̻��� ���� ���μ����� ž���ߴ�. ���� ������ ������ ������ǻ�Ϳ��� ���� ��� �ý����� ������ ������ 91�ۼ�Ʈ�� ���Ѵ�. �̹� 11�� ����Ʈ �� ������ ���� 7���� �� �ý����� ���� ���� Phi �����μ����� ž���ߴ�. �׳� ����(University of Tennessee)�� ������(Beacon)�� �ý��� (110 ���÷ӽ�, 254��)�� ����Ʈ�� ���� ���� ȿ������ ������ǻ�ͷ� ��Ʈ�� 2.44�Ⱑ�÷ӽ��� ������ �����Ѵ�.
��ü ����Ʈ�� www.top500.org���� Ȯ�� �����ϸ�, ���̾� ����̾�Ʈ(Diane Bryant)�� ��ǥ �� �ڼ��� ������ �߰� �ڷ�, ������ http://www.intel.com/newsroom/sc12���� Ȯ���� �� �ִ�.