�ھ� i7-12700KF�� �ھ� i9-12900KF �� ���� CPU�� ���並 ���� ������
12���� �ھ� CPU�� ���� ����ũ�� 11���� ��� ���ɰ� ������ ���� ��ȭ�� ���� Ȯ���ߴ�. ���ٸ� � ������
�̷��� ���� ������ �̲��� �´��� �ñ��� ���� �ѵ�, �̹� ��翡���� �ռ� �ھ� i7-12700KF ���� ��翡�� �����ߴ�
���� ���� ����ũ ���� ����� ���, ��Ű��ó ���� ������ �����ϰڴ�.
��-��Ʋ�� �ٽ�, �ʿ��� �۾��� ������ ���� �ﰢ �Ҵ��ϴ� ������ ����
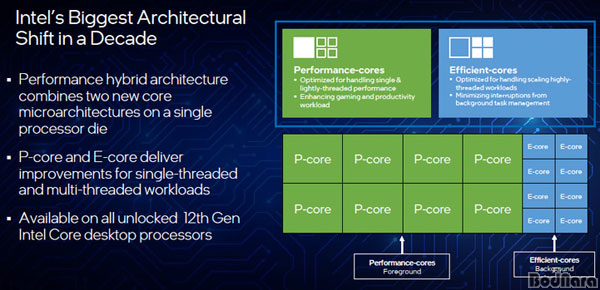
���� ����ũ�� ��-��Ʋ�� ���´ٴ� ���� ����� ���� ����� ��Ҹ��� ���� ����, ���ݱ���
������ ��Ű��ó�� �ھ�θ� �����Ǿ��� x86 CPU ���ʷ� ������ CPU �ھ�(P-�ھ�)�� ���� ȿ���� ���� CPU
�ھ�(E-�ھ�)�� ���յ� ���̺긮�� Ÿ���̶�µ� �ִ�.
�������̳� �������μ��� ���� ���� ������ �ʿ�ġ ���� ������ �ʿ���� �۾��̶�� �ش�
�۾��� ��� �ھ �Ҵ�Ǿ ������ ������, �������̳� ������ ����/ ��ȯ ���� ���� ������ �䱸�ϴ� �۾��� E-�ھ��
�����ٸ� ������ �ȴ�.

�̿� ������ �ϵ���� �����ٷ��� ������ ���� ���� �۾� ������ ��︮�� �ھ �ﰢ
�Ҵ��� �� �ֵ��� �ߴ�. �ϵ���� ����� ��ŭ �ü���� ������ ������, ���������� �۾��� �Ҵ��ϴ� ���� �ü��
�����ٷ��� ������ ��ŭ OS �ܿ����� ������ �̷������Ѵ�. ���� ���� ����ũ�� ���� x86 ���̺긮�� ��Ű��ó CPU��
����ȸ�� �����ٷ��� �����ϴ� ù OS�� �ٷ� 10�� 5�� ��õ� ������ 11�̴�.
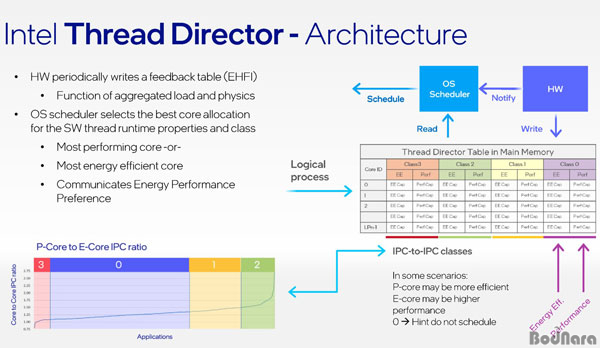
������ ���ʹ� �⺻������ E-�ھ�� ����� �۾�, P-�ھ�� ������ �۾���
�Ҵ��ϰ�, ���ɰ� ���� ���¿� ���� ũ�� �� ������ �з��� ���̺� ������ ������ ������ ������ �� �ھ��� ���¸� Ž��,
�۾����� ������ �ھ �����带 �Ҵ��ϴ� ������� �����Ѵ�.
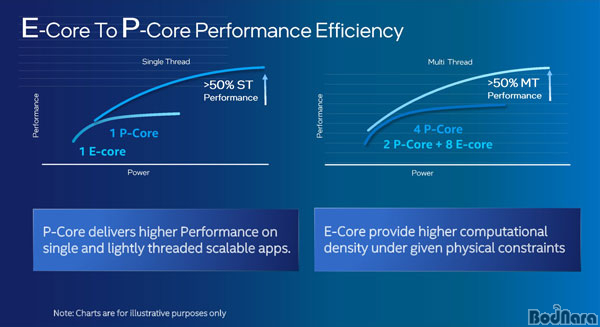
�̸� ���� ���� ����� �۾��� ������ �۾��� ���� ��ȯ�Ǵµ��� On/ Off �Ǵ�
������ PC ���� ȯ�濡�� ������ ���ɰ� �Һ������� ������ �� �ְ� �����Ѵ�. ����, ������ ���ʹ� �ھ��� ���� ������
������ �Ҵ��� ����������, ���� �̸� ���� �����ϴ� ���� �ü���� �����ٷ���.
���� �ü�� �����ٷ��� ���� ���� ����ũ�� ���̺긮�� ��Ű��ó�� ����� �����ϴ� ����
������ ����� Ȱ���ϴµ� �־� �߿��� ���� �� �ϳ��̸�, �� �������� ���� ���� ����ũ�� ���̺긮�� ��Ű��ó�� ����
�����ϴ� �ü���� ���� 10�� 5�� ��õ� ������ 11�� �����ϴ�.

����, ������ ���ʹ� �ڵ����� ������ �ھ�� �����忡 �۾��� �Ҵ�������, ������
�����ڵ��� ���� ũ�� �� ���� ����ȭ ����� �����Ѵ�.
ù°�� ��ü������ P-�ھ�� E-�ھ �۾��� �Ҵ��ϵ��� �δ� ���̴�. ��쿡 ����
��ũ�ε尡 �������� ���� �ھ �Ҵ�� �� �־�, ������ ���ø����̼��� ������ ������ ���� �Ʒ� �� ���� �� �� ����
��츦 �����ϵ��� ���Ѵ�.
�� ��°�� �������� �䱸�Ǵ� �ֿ� ��ũ�ε��� �켱������ ���� P-�ھ �Ҵ�, �����
�۾��� �켱 ������ '����' �̸����� ���߰� �ʿ��ϴٸ� E-�ھ �Ҵ��� ������ �켱 �ϴ� ��.
���������� ������ Ǯ�� P-�ھ� �Ҵ�� E-�ھ� �������� ������ ���ɰ� ȿ���� ���
�븮�� ������, �� ��° ����ȭ�� ���ؼ��� 'Good', ������ ����ȭ�� ���� 'Best' �ó������� �з���, �� ��°
����ȭ�� ��� �Ϻ� ����� �۾��� P-�ھ �Ҵ�� �� �ִ� ��쵵 �����ϵ��� ���Ѵ�.
�а�, ����, ����Ʈ�� ó��, ��� �ں� P-�ھ� ��Ű��ó

������ ���� 2018��, 6���� �ھ� CPU ���� �����ؿ� '����ũ' �ø����� �ļ�
CPU ��Ű��ó�� '���� �ں�'�� ��ǥ�߰�, ���̽� ����ũ�� ������ ����� ���μ����� �켱 �����ؿԴ�. ����� Ÿ�̰�
����ũ�� ����� '���ο� �ں�' ��Ű��ó�� 14nm ������ ��Ű��ó�� '���������� �ں�(Cypress Cove) ��Ű��ó��
����ũž�� 11���� �ھ� CPU�� ���� ����ũ�� ����ȵ� �̾�, 12���� �ھ� CPU������ ����� �÷����� ���ÿ� �ƿ츣��
��� �ں� ��Ű��ó�� P-�ھ ���Ǿ���.
��� �ں� ��Ű��ó�� ���� �ں�� ���������� �а�(Wider), ����(Deeper),
����Ʈ�ϰ�(Smarter)�� �� ������ �����ϸ鼭, �ӵ��� �����Ͻ� �� �̱� ������ ���ø����̼��� ���� ������ ������ ����
Ư¡�̴�. ������ �ھ� i7-12700KF ��Ʈ ����� ���� �̱� ������ ������ ���� ������ ���� Ȯ���� �� �־���.

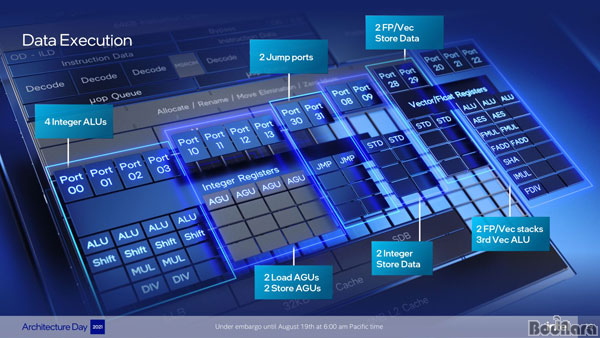
���� ����ũ�� P-�ھ ����� ��� �ں� ��Ű��ó�� �⺻������ ����� ���� �����ٷ���
����, ���� �������� Ȱ���ϸ�, �Ҵ�â(Allocation Window)�� ������, �� ���� ���� ��Ʈ�� �����ϴ� ����
Ư¡�̴�.
��� �� ����Ʈ���� �б� ������ ���� ����ȭ ���� �� ������ ������, �ھ�� ����
���� ��Ʈ�ѷ��� ������ ����ũ���� ������ ���� ���¸� Ž��/ ������ �� ���ø����̼ǿ� ����ȭ�� ���� ���� �� �� ������
��� Ŭ�� ������ ����������.

���� ���������� ���� ���ڴ��� 4������ 6����, ����ũ��op ij�� �ǵ�� ����Ŭ��
6���� 8�� �þ���, �̿� ���� ����Ʋ�� ���ɾ� ��ġ(fetch) �뷮�� 16byte���� 32byte�� �� �� �þ���,
����ũ��op ij�õ� 2.25K���� 4K ��Ʈ���� Ȯ��Ǿ���.
����ũ��op ť�� ������� 70���� 72��Ʈ���� Ȯ��, �̱� ������� �ִ� 144��Ʈ����
�����ϸ鼭 ����� ���� ������ �ӵ��� ���̰� ����ũ��op ���߷��� �����ߴ�.
4K iTLB((instruction Translation Look-aside
Buffers)�� 128���� 256��, �б� Ÿ�ٵ� 5K���� 12K�� ���� ��ȭ�ߴ�. �б� ���� �������� ���̱� ���� �б�
������ �����ϰ� BTB(Branch Target Buffe)�� �� �� �̻����� �����ߴ�.

����, ����� ���� ������ ��ġ ������ 5������ 6����, ���� ��Ʈ�� 10������ 12����
�ø���, �� ������ ���۵� 352���� 512�� ũ�� �÷ȴ�. �̸� ���� �����̹�/ ��ġ �� �Ϻ� ������ ���� �����
���Ӽ� ü���� ���, ���� ���������ο��� ���ԵǴ� ���ҽ��� ���̰� �ٸ� ������ ���� ������ �����ϰ� ���� ȿ���� ����� ��
�ִ�.
���� �� ���� ���� ���ְ� �����ؼ��� ALU�� LEA�� ���Ե� �ټ� ��° ���� ����
������ �߰��Ǿ���, ���� ����, 1���� 5�� ��Ʈ�� FADD(Fast ADDers)�� �߰��ϰ�, FMA���� AVX512���
FP16 ������ �����ϵ��� ����������, �ƽ��Ե� ���� ����ũ������ ������ �ʴ´�.

�ھ�� ij�� �뷮�� L1 ������ ij�� 48KB, L1 ���ɾ� ij�� 32KB��
�����Ǿ�����, L2 ij�ô� 512KB���� 1.25MB�� �� �� �̻� ����������, L3 ij�� �뷮�� �ھ�� 2MB����
2.5MB�÷� Ȯ�� �Ǿ���.
�ܼ� �뷮 Ȯ�� �� �ƴ϶� L1 ij�� �ε� ��Ʈ�� 2���� 3����, L1D ij���� ������
��Ŀ�� 2���� 4��, L1D TLB�� 50% �ø��鼭 �� ���� ������ ����ȭ�� �����ߴ�. ij�� �뷮 ������ �����Ͻ� ������
����������, ���ο� ������ġ ������ ���� �������� ���α��� ������ �� ������ ������ Ư���� ������ ��θ� ������ġ��
������ �� ������ �˷ȴ�.

����, ���� ����ũ P-�ھ���� �������� ������, ��� �ں� ��Ű��ó����
AMX(Advanced Matrix Extensions)�� �����Ѵ�. �����ͼ��� AI ������ ���� ��� ���� ���ӿ�
���ɾ��, �߷а� ����н� � �پ VNNII ��� 8���� ó�� ������ ������ �� �ִٰ� �Ұ��Ǿ��µ�, ������ ������
���� �����Ϸ��� ���μ����� �ڵ���� �����̾� ������� ���� �� �ְԵ� ���̴�.
���� ȿ�� �켱, ���̽���Ʈ ��Ű��ó E-�ھ�

�ַ� ����� �۾� ó���� �켱 �Ҵ�Ǵ� E-�ھ�� Ư���� P-�ھ�� ���� ������
����������, ���� ��ī�̷���ũ �ھ� ��� ���� ���¿��� 40% ���� ������ �����ϰ�, ���� �����̶�� ���� �Ҹ�
40%���� �ھ��.
���� ����ũ�� E-�ھ� 4���� ���յ� ����� ��ī�̷���ũ 1�ھ���� ���� ũ���
����Ǿ�����, ���� ����
������ ��� ��ī�̷���ũ 1�ھ� 2������ ��� ���� ����ũ E-�ھ� 4�� ����� 80% �� ���� ������ �����Ѵ�.

���� ���� ����ũ E-�ھ��� ���̽���Ʈ ��Ű��ó�� 5õ �б� Ÿ�� ij�� ����Ī�� ����
�б� ���� ��Ȯ���� ���δ�. ���ڿ� ������ �̷��� �� ���(history) ��� �б� ���� �ý����� ���ɾ� ��������
��Ȯ���� ���̴µ� ������ �ָ�, ��������� ���ɾ� ij�� �̽� ���°� ���α� ��� ġ������ ���ؿ� �����ϱ� �� �߰��ϰ�
������ �� �ְ� ���ش�.
����Ʈ ������ L1 ���ɾ� ij�ø� P-�ھ��� 32KB ��� �� �迡 ���ϴ� 64KB
�뷮�� ��ġ�� ���� ���ɾ �����ϰ� ������ ���� ������ �����ϴ� ����, ���� ������ �ֹ��� ���� ���� ���ڴ��� ž���ߴ�.
�ش� ���ڴ��� ���ɾ� ij�ÿ� �Բ� ����Ǵ� ���� ���ڵ� ������ ����, �ռ� ���ɾ���
����� ������ �ͼ��� �ڵ尡 ���� ���ڴ��� ��ȸ�� ������ ��� ��Ѵ�. ��������� ���ڴ��� ��� 3���̵� ���ڴ�����
Ŭ������ȭ�Ǿ� ����Ŭ�� �ִ� ���� ���� ���ɾ ���ڵ��� �� ������, ���� ó���� ���� �ϵ���� ��� �ε� �뷱����
�����ȴ�.
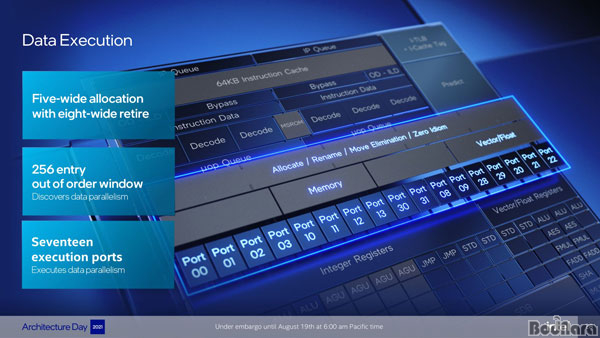
�鿣�� �ܿ����� 256 ��Ʈ�� ����� ������� 5-���̵� ������̼�, 8-���̵� ��Ÿ�̾�
�������� 17 ���� ��Ʈ�� ����Ǹ�, �̷��� ������ �Ϻ� ���� ���¿��� ��ī�̷���ũ���� ���� ���� IPC�� �����Ѵ�.
���� ����Ŭ �� 2���� �б⸦ �ذ��� �� �ִ� ��� ���� �¼� �� �й�⸦ ���� 4����
�Ϲ� ���� ���� ��Ʈ�� �����, VNNI ���ɾ ���Ǵ� ���� �¼�(integer multiplier)�� ����
SIMD ALU�� �� ���� �����.
�� ���� ��Ī �ε� �Ҽ��� ������������ �� ���� �������� ���ϱ� �� �� ������ ������ ��
�ְ�, ���� Ȯ���� ���� ����Ŭ�� �� ���� FP ������ �� ���ϱ� ������ ������ �� �ִ�. 2���� AE �� 1���� SHA
���� ������ �����.

�� �ý����� ���ÿ� 32KB �б�/ ���Ⱑ ������ ��� �ε�/ ����� ������������
���߰� ������, �ھ L2 ij�ð� �Ҵ�� P-�ھ�� �� E-�ھ��� L2 ij�ô� 4�� �ھ��� ���������� 2MB��
�����Ѵ�.
E-�ھ��� L2 ij�ô� �ھ�� 1MB�÷� P-�ھ��� 1.25MB���� �뷮�鿡�� ���� ����
�� �� �ִ�. 17����Ŭ �����Ͻÿ��� ����Ŭ�� 64byte�� �뿪���� �����ϸ�, �ھ�� ���� �ٸ� ����Ʈ���� �����尣
���ҽ��� �����ϰ� �й��ϴ� ���ҽ� ���� ����� ���ԵǾ���.
����, ���̽���Ʈ ��Ű��ó E-�ھ��� L2 ij�ô� �ִ� 4MB ������ �����ѵ�, �Ϲ�
�Һ��ڿ� ���� ����ũ�� 2MB�� �����Ǹ�, L2 ij�� 4MB�� ������ �����ͼ��Ϳ� �ھ ž��� �����̴�.